语音分类¶
本篇文档将介绍如何使用 Mind+ > 程序设计 > 实时模式 下的 模型训练推理库——语音分类功能模块 ,应用 自行训练的语音分类模型 ,完成音频分类项目。
功能介绍¶
通过语音分类功能模块,用户可以加载训练好的语音分类模型,对麦克风输入的音频进行实时推理分类,并获取对应的类别 ID、标签及置信度等结果。
以此,用户不仅可以快速应用自训练的语音分类模型制作各类音频分类项目,判断音频所代表的事件或情绪特征,还可以直观观察声音的频率、强度、时长、节奏等多维度特征,理解体验声音输入、模型推理、结果输出的完整应用流程。
准备工作¶
硬件准备¶
- 一台电脑
- 麦克风
软件准备¶

安装V2.0.4及以上版本的Mind+编程软件,点击查看Mind+安装教程。如何检查软件版本,见常见问题解答
模型准备¶
在制作图像分类项目之前,需要先训练并导出一个语音分类模型。 可使用 Mind+ V2.0 模型训练工具 中的 语音分类模块 完成模型训练,并将模型导出用于后续推理,导出的语音分类模型为一个以 **.zip** 为后缀的压缩包。后续项目中,将直接使用该压缩包加载语音分类模型并进行语音分类任务推理。

自行参考以下教程,准备一个图像分类模型用于后面项目制作。
图像分类模型训练教程:语音分类-训练模型
图像分类模型导出教程:语音分类-模型导出
加载模型训练推理库¶
打开 V2.0.4及以上版本的Mind+ ,点击进入'实时模式'。
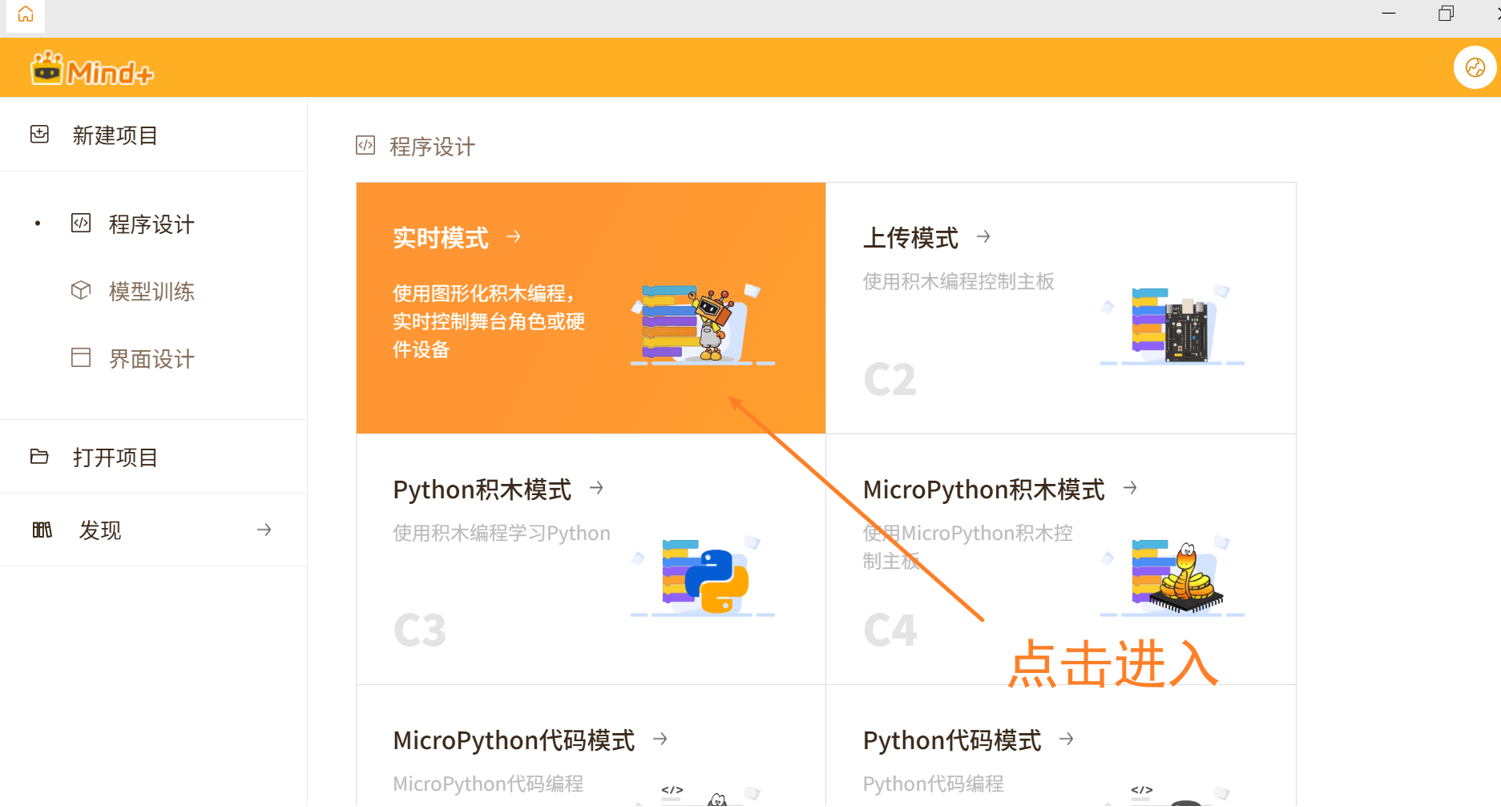
在实时模式下,点击左下角’扩展‘,在舞台扩展中找到 '模型训练推理库',点击加载。
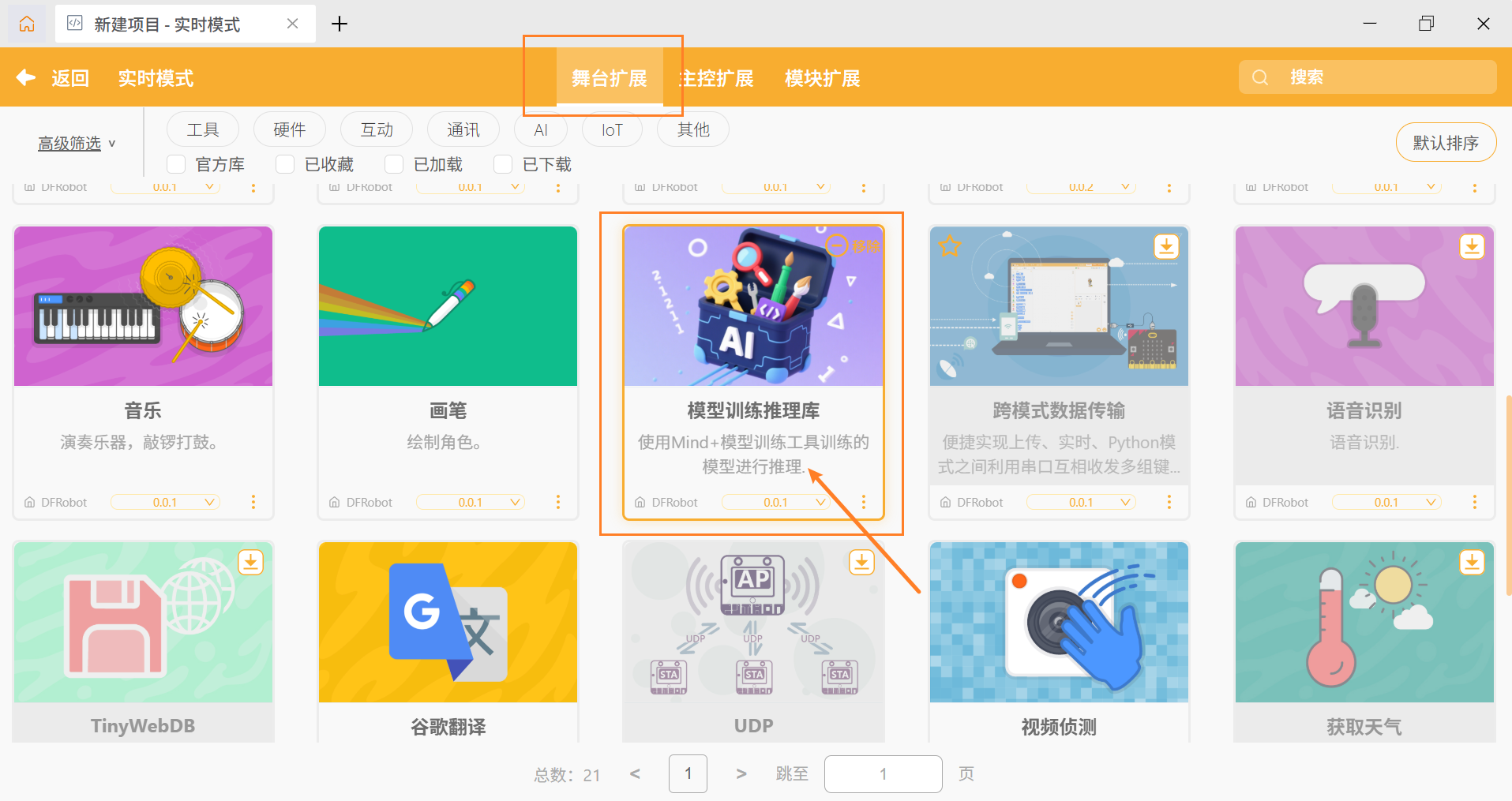
加载成功后,返回实时模式编程页面,点击 '模型推理' 下的 '语音分类' ,可以找到语音分类积木块,如下所示。

使用逻辑说明¶
项目:听声音辨乐器¶
本项目演示如何使用 已训练好的语音分类模型 ,对从麦克风获取的实时音频进行分类推理,获取对应的分类结果,实现听音乐辨乐器。
在本示例中,使用的示例模型为能分辨三种乐器音色(钢琴、吉他和架子鼓)的音频分类模型。 在实际使用中,你可以将示例模型替换为 自己训练或已有的语音分类模型 ,其余代码流程保持一致。
示例程序¶
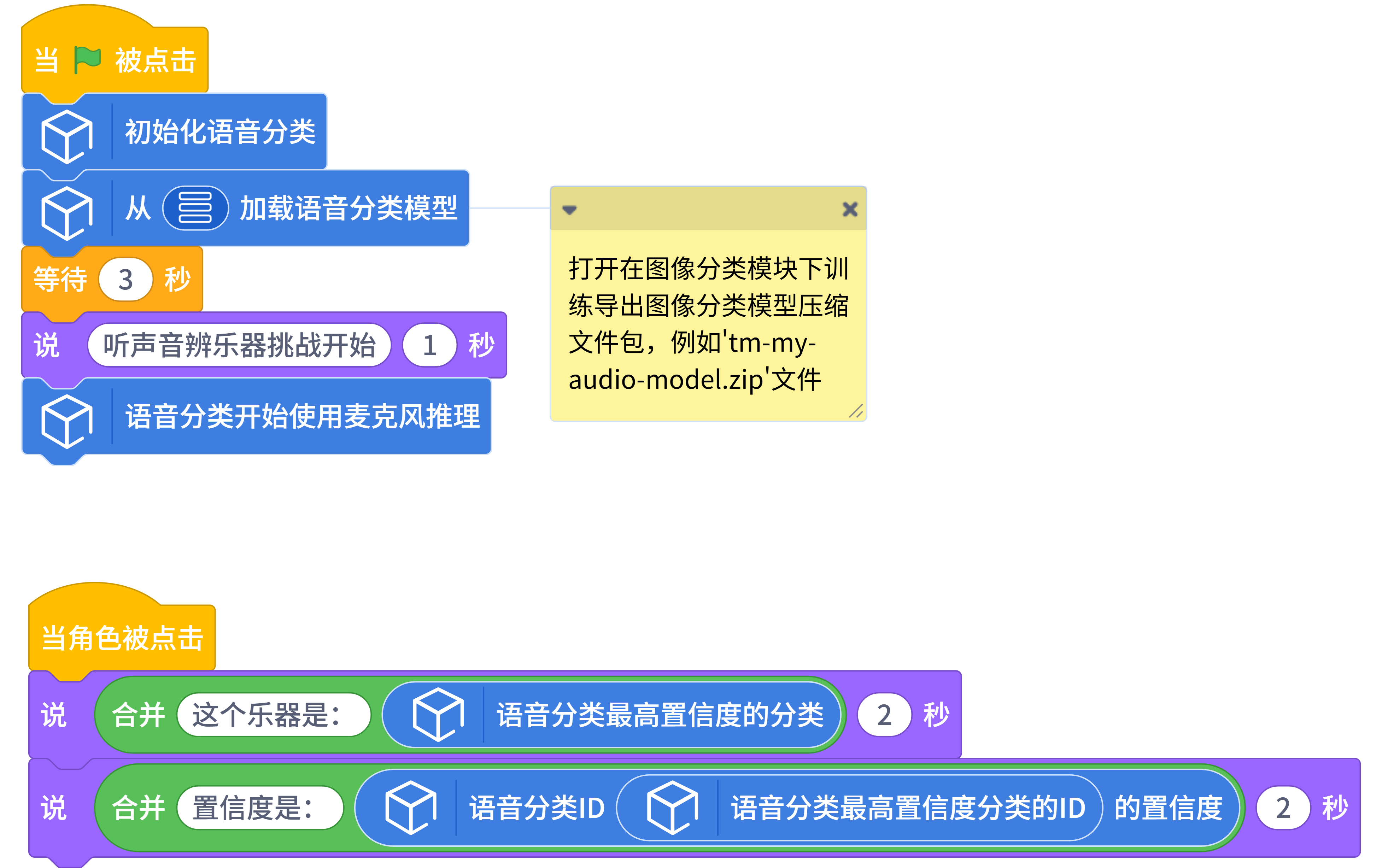
运行效果¶
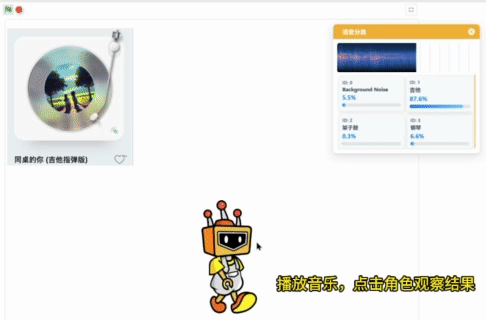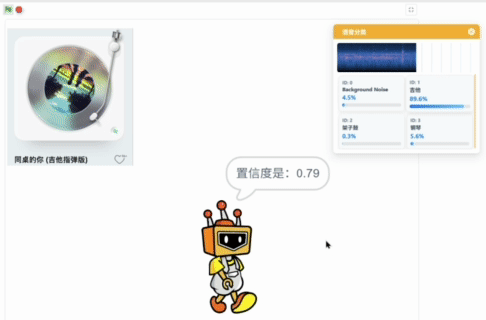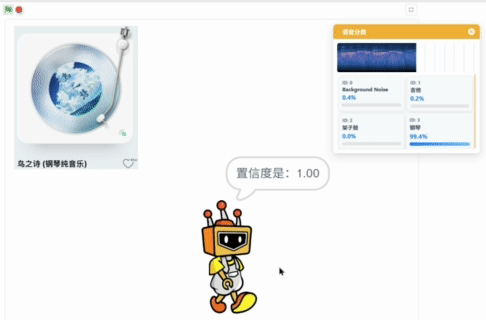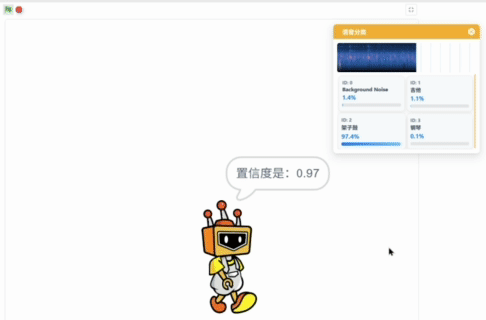
运行程序后,语音分类模型加载成功后,弹出模型推理窗口,可以观察麦克风实时输入的声音,下方显示语音分类模型实时的推理结果,以置信度最高的标签作为最终的分类结果。
播放不同的音乐,点击Mind+角色,角色说出当前音乐对应的乐器名称和置信度。

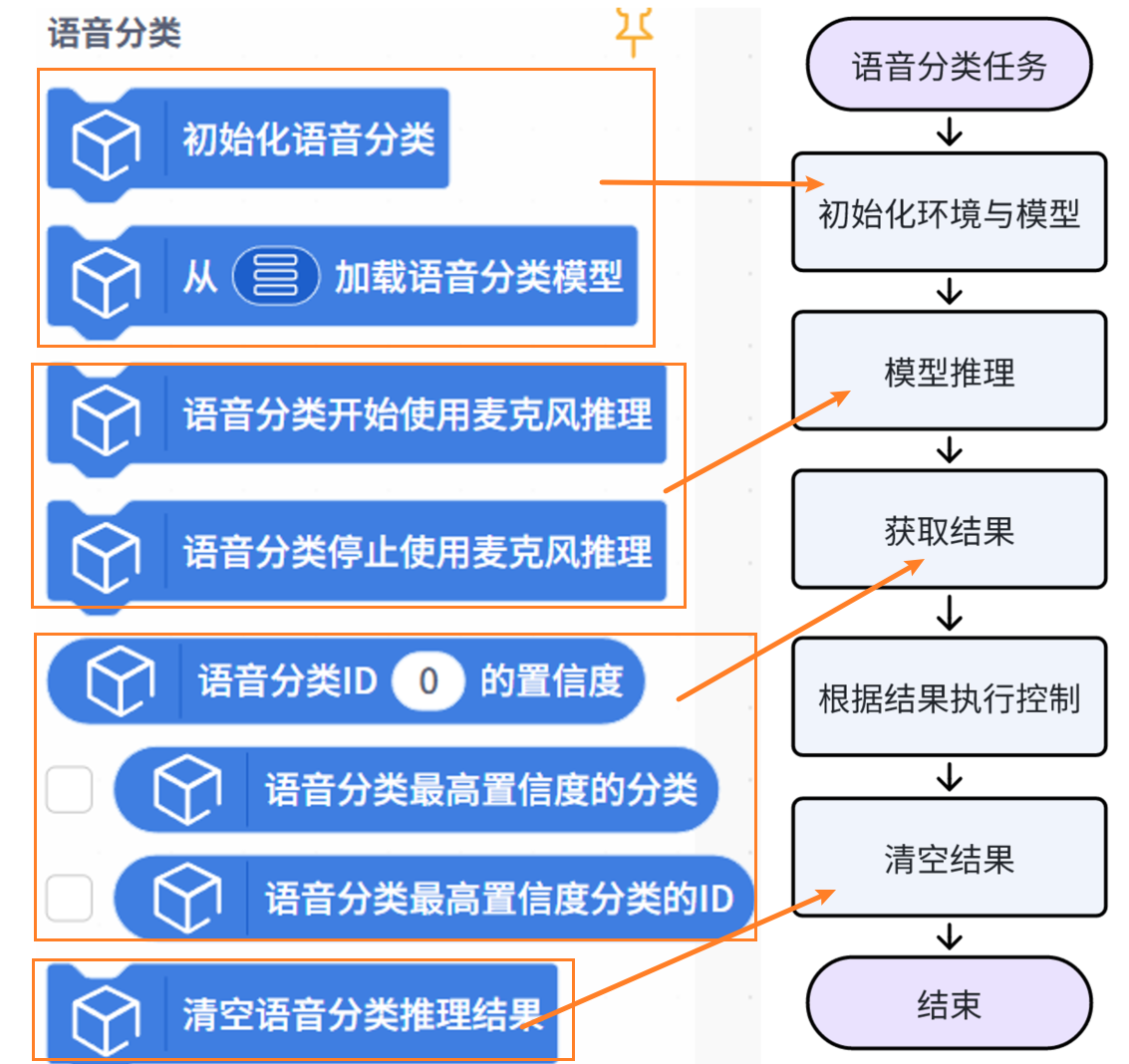
积木说明¶
| 语音分类积木 | 功能说明 |
|---|---|
 | 初始化语音分类任务。 使用语音分类相关积木功能前,需要先执行该积木。 |
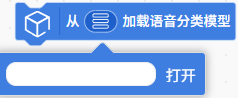 | 从本地加载已经训练好的语音分类模型文件,用于语音分类推理任务。 这里的语音分类模型为在模型训练-语音分类模块下训练导出的模型压缩文件,例如 'tm-my-audio-model.zip '。 |
 | 对麦克风采集的实时声音进行连续的语音分类推理。 |
 | 停止麦克风采集音频与语音分类推理 。 |
 | 获取语音分类结果中,指定类别 ID 对应的置信度数值。ID 填入从 0 开始的整数,也可使用 int 类型变量。 |
 | 获取当前语音分类结果中,置信度最高的分类标签。 常用于直接作为最终语音分类标签结果。 |
 | 获取当前语音分类结果中,置信度最高的分类对应的类别 ID。 |
 | 清空当前已保存的语音分类推理结果。 |
常见问题解答¶
| Q | 如何检查Mind+软件版本号? |
|---|---|
| A | 打开Mind+编程软件,点击右上角系统设置图标。 V2.0.4及以上版本的Mind+ 的系统设置面板中新增一栏 ' 版本更新 ',点击' 版本更新 ',可以查看当前Mind+软件版本。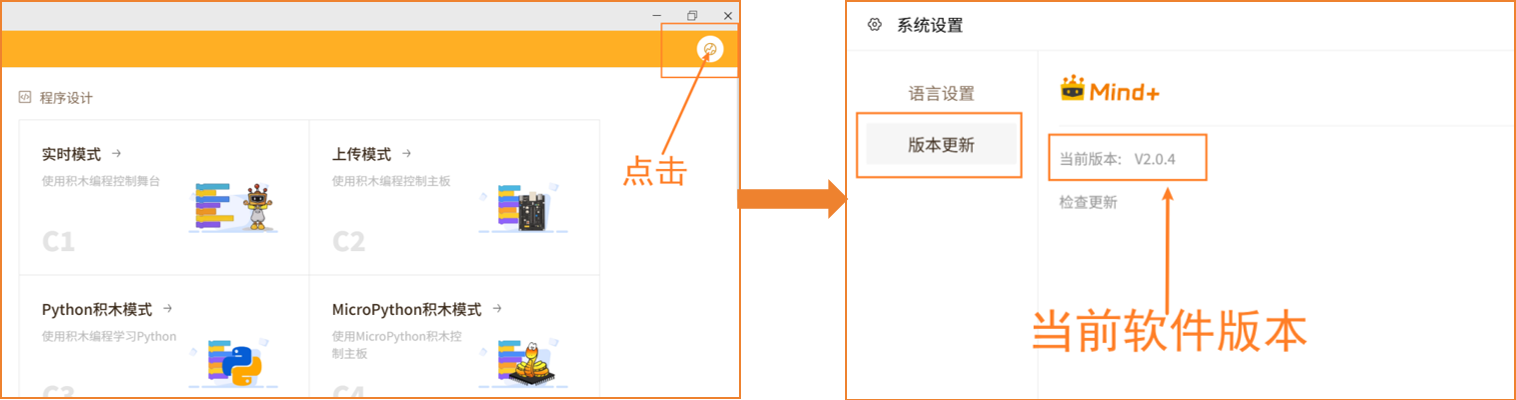 |