4.2.6 【文本分类】 快速体验
文本分类-快速体验¶
文本分类的快速体验操作步骤以“电影评论倾向文本分类”案例为例,带领用户学习文本分类模型的完整训练流程。该案例旨在直观演示文本分类在实际场景中的应用效果:模型能够对输入的电影评论文本进行识别与分类(如区分 “正面评价”“负面评价”“中立评价”),帮助用户清晰理解文本分类的核心原理(基于文本语义、情感词等特征提取与类别匹配)与应用价值(如电影口碑分析、观众反馈收集、影视平台评论筛选等)。
- 效果: 能准确区分 3 种常见电影评论情感类别,包含正面评价、负面评价、中立评价
快速体验文本分类模型训练实现过程分为五个步骤:
- 新建项目 —— 创建文本分类项目并准备数据集;
- 类别及对应样本添加 —— 添加待识别的文本分类标签(如 “正面评价”“负面评价”“中立评价”),并通过手动输入(或上传文本TXT文件)的方式获取对应类别的文本数据集;
- 训练模型 —— 通过平台训练得到文本分类模型;
- 模型校验 —— 测试模型效果。
- 模型部署 —— 模型训练完成后,可以将其导出并部署到硬件设备,实现本地运行与应用。同时,用户还可以选择将模型的识别结果实时推送到SIoT平台,便于远程监测与管理。
步骤1:新建项目¶
- 打开 Mind+,在菜单栏中选择 “新建项目”,然后点击 “模型训练”。
- 在训练选项中找到 “文本分类(M6)” 并点击,即可完成项目创建。
- 项目创建成功后,将自动跳转至新的文本分类快速体验界面。
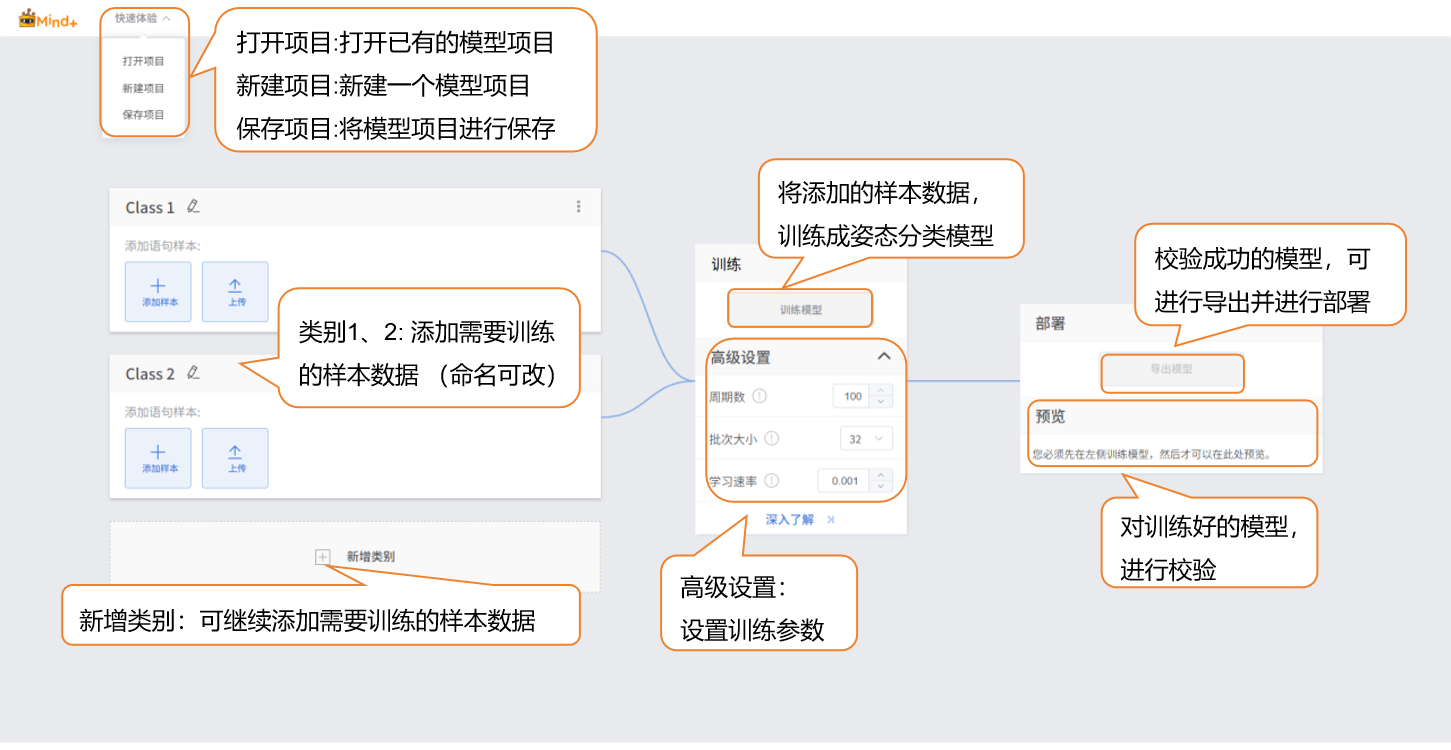
步骤2:类别及对应样本添加¶
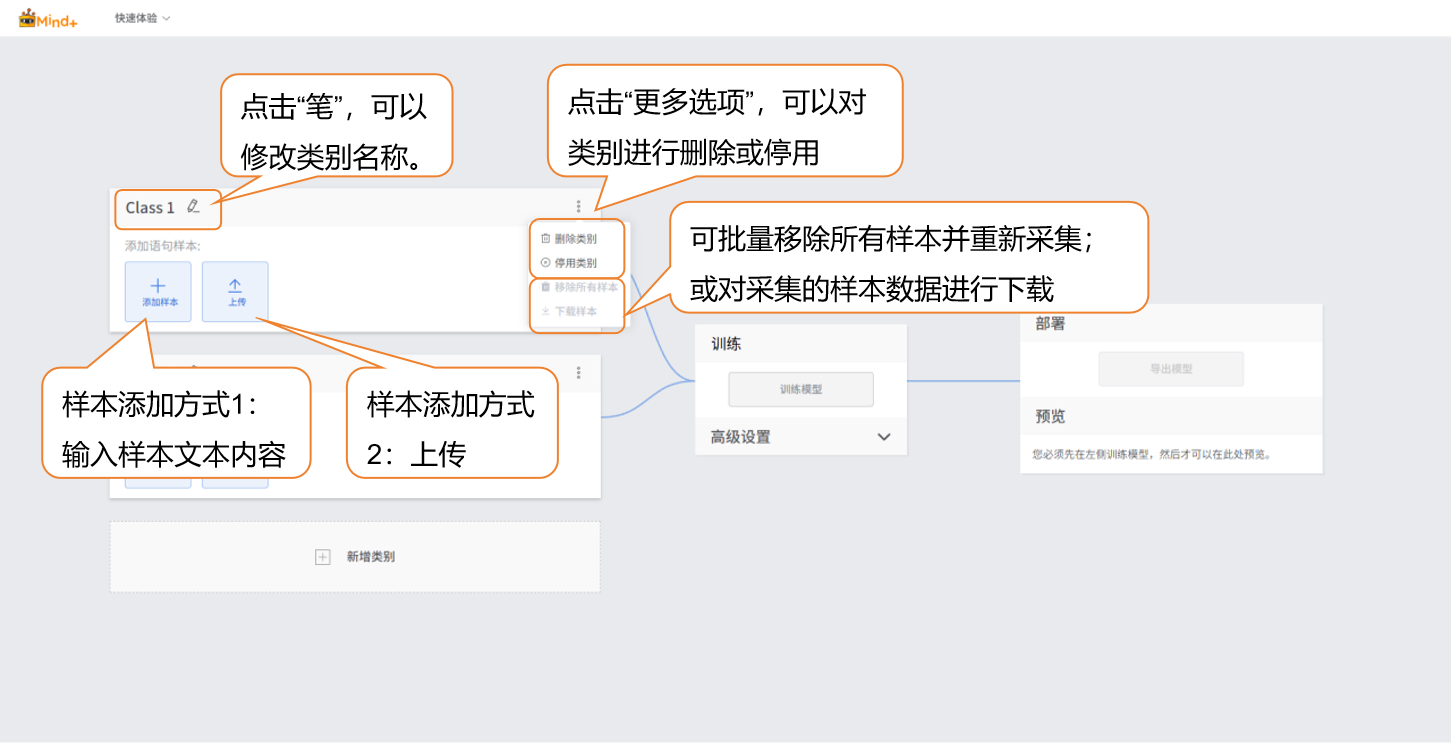
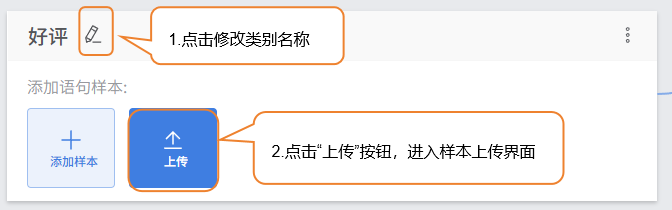
- 点击笔,修改类别名称,添加对应文本样本数据。
-
样本可通过以下两种方式添加,用户可根据实际需求灵活选择:
-
手动输入: 适合现场生成少量干扰文本(如输入 “asdfg12345”“今天天气真好,和电影无关” 等无关内容),操作便捷,能快速匹配当前场景干扰特征;
-
本地上传: 适合导入已准备好的批量文本素材(如提前整理的好评文本TXT 文件)便于高效管理文本数据
-
通过这两种方式,用户能够灵活地构建数据集,为后续的模型训练做好准备。
-
命名类别
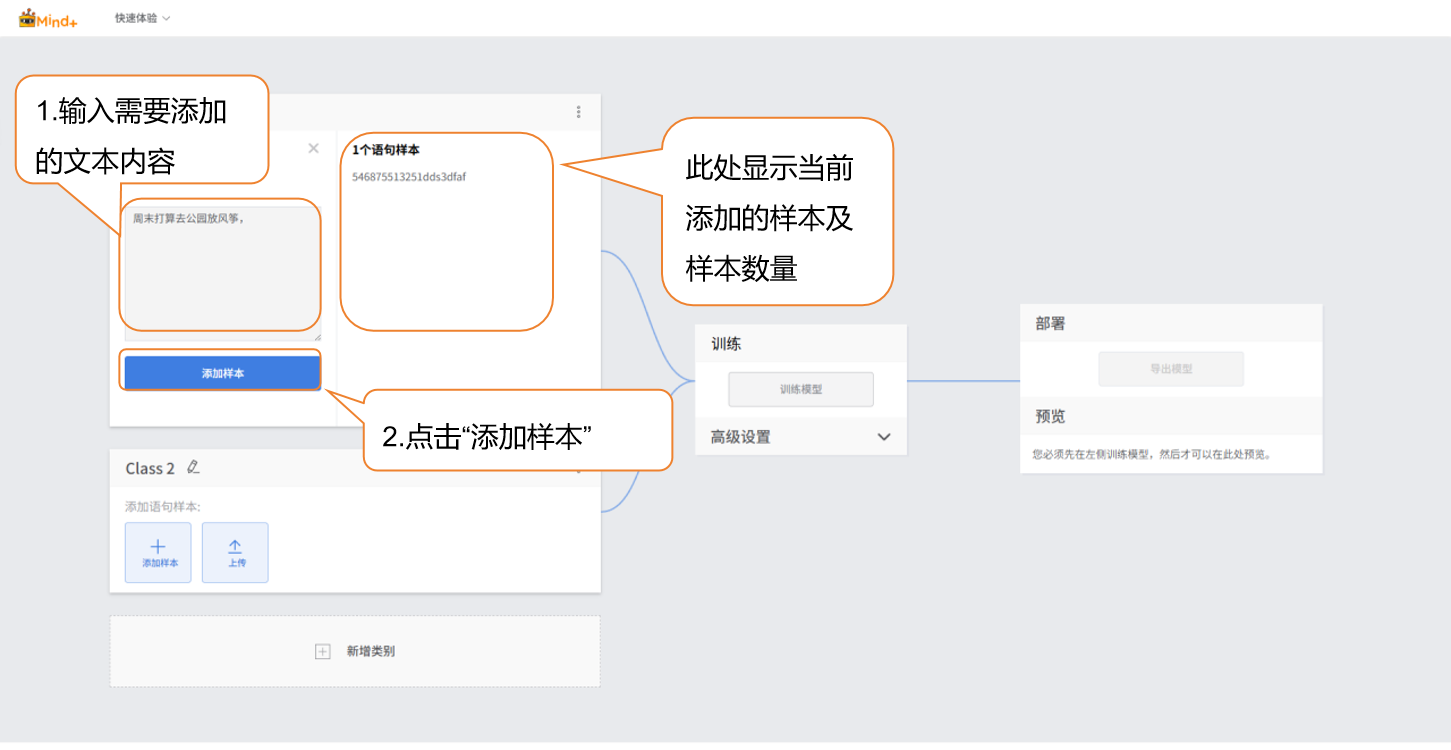
- 继续修改下方默认生成的 “Class1” 标签,点击标签旁的笔型按钮,修改类别名称为具体文本类型(如 “干扰文本”),完成该文本样本的类型命名。
-
样本添加方式1:手动输入
-
点击界面中的 “手动输入” 按钮,系统将弹出文本输入框,输入单条干扰文本(如 “qwertyuiop”“这不是电影相关内容”),每条文本长度建议控制在 10-200 字符(避免过短无意义或过长增加模型负担)。
-
-
输入完成后点击 “添加样本” 按钮,文本将自动归入干扰文本样本类别;若需补充样本,可重复 “输入文本 - 添加样本” 操作,直至样本数量达到预期建议确保覆盖多种干扰类型。
-
-
可对添加的干扰文本样本进行单独删除、批量删除或批量导出(导出格式支持 TXT),便于样本管理与更新。
- 该类型样本采集完成后,点击输入框右上角 “×” 退出输入界面。
-
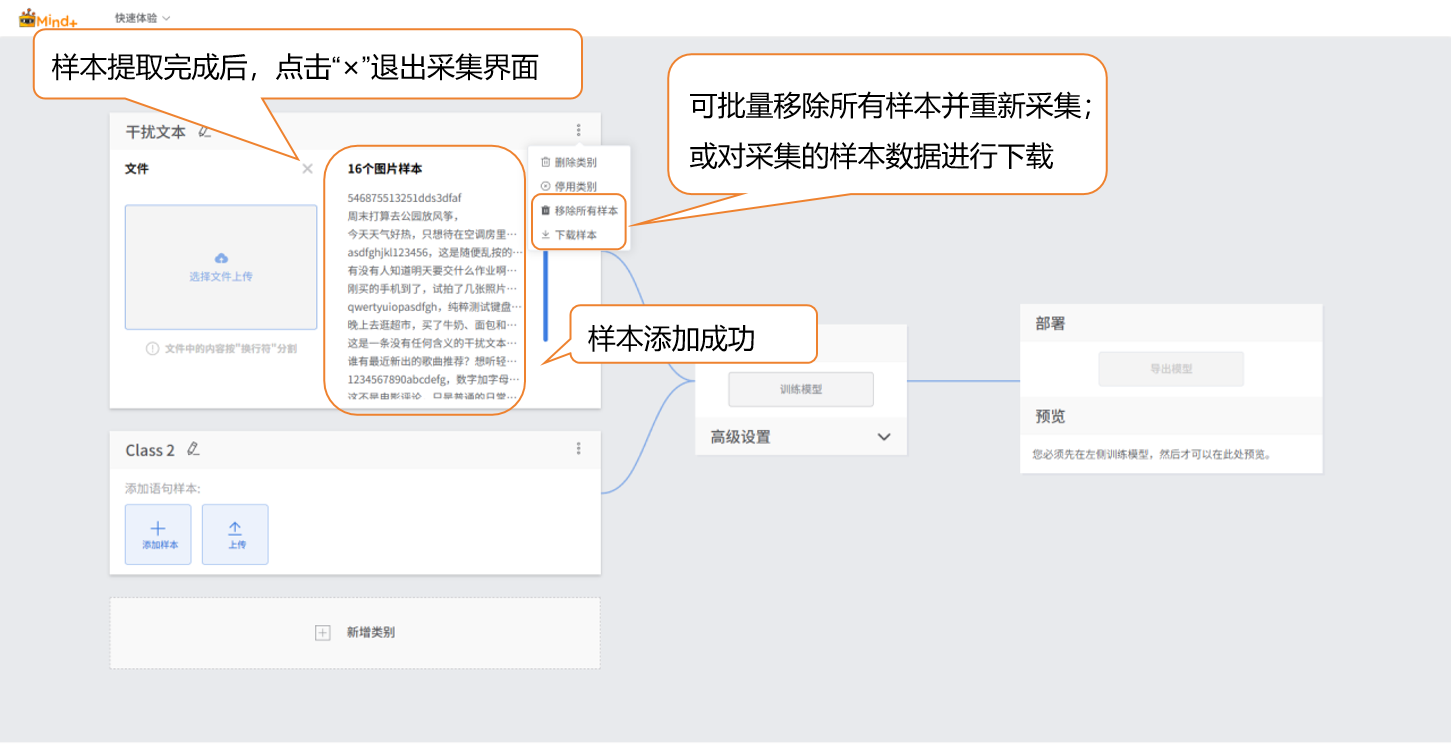
-
样本添加方式2:本地上传
-
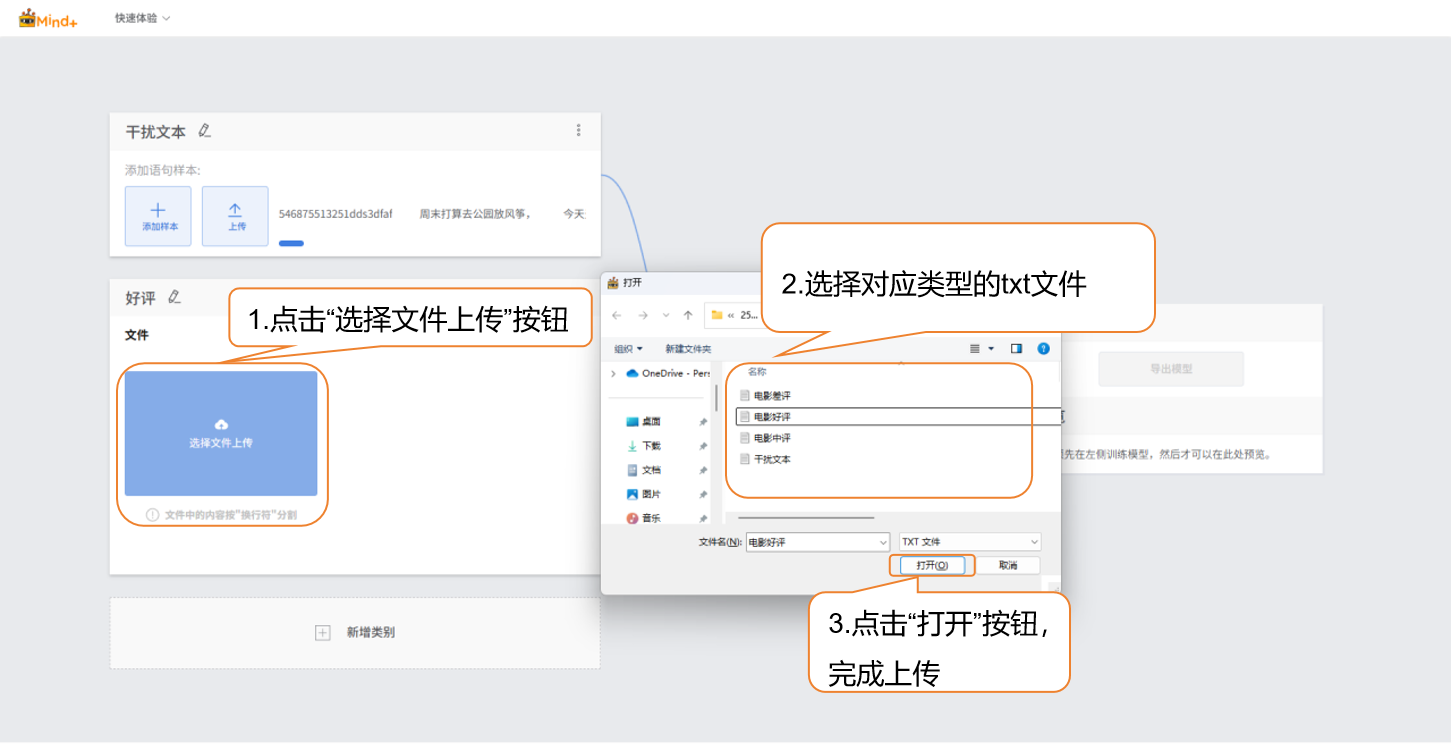
首先继续修改下方默认生成的 “Class2” 标签,点击标签旁的笔型按钮,修改类别名称为具体文本类型(如 “好评文本”),完成该文本样本的类型命名。
-
点击 “上传” 按钮,进入文本样本上传界面。
-
点击 “上传” 按钮,进入文本样本上传界面;点击 “选择文件上传”,选择本地提前整理的电影评论文本文件,支持TXT格式。
-
注:文件中的内容需要按“换行符”分割(即一句/一词 换一次行)
-
-
完成样本上传。点击“×”退出采集界面。
-
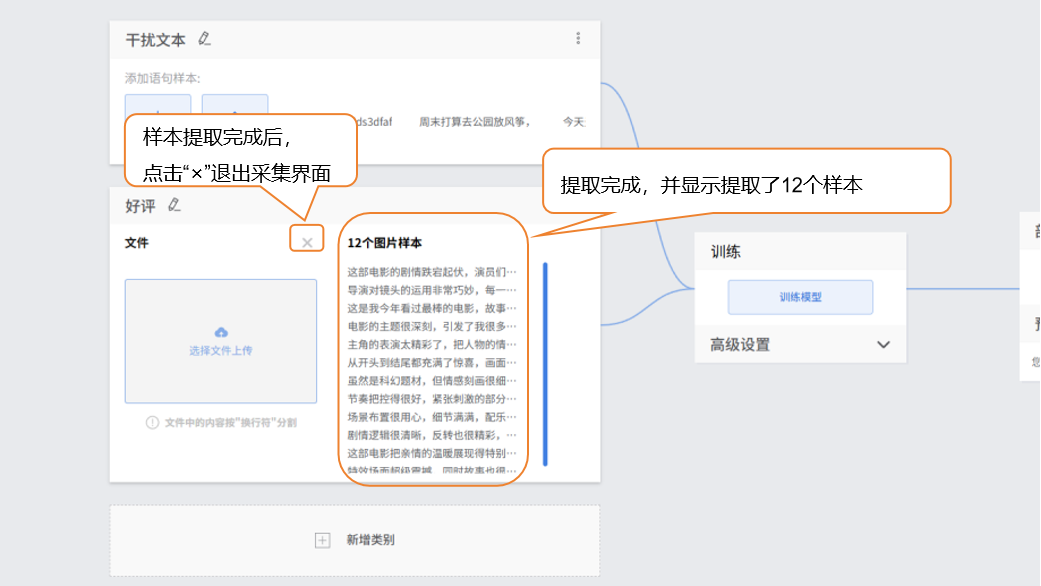
-
可在此基础上继续上传添加新样本,采集补充
-
-
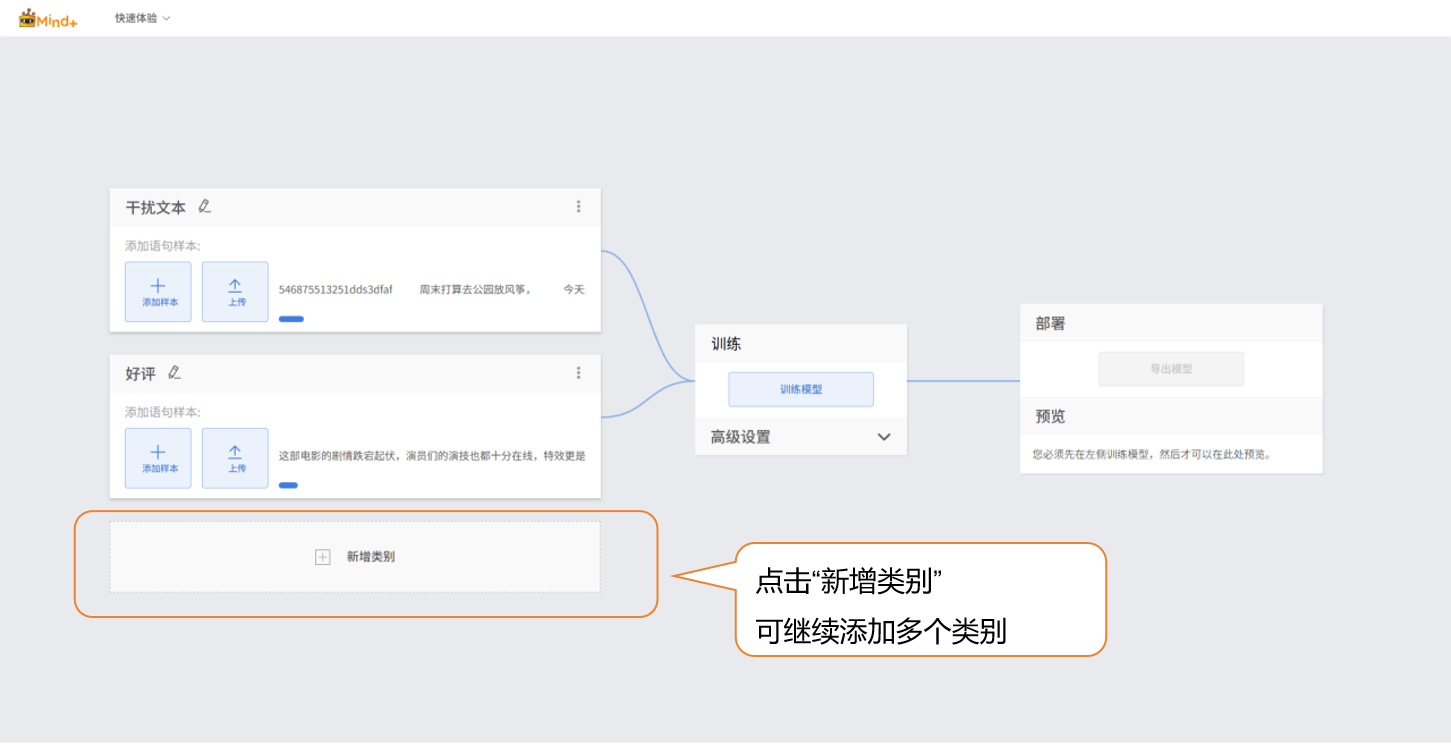
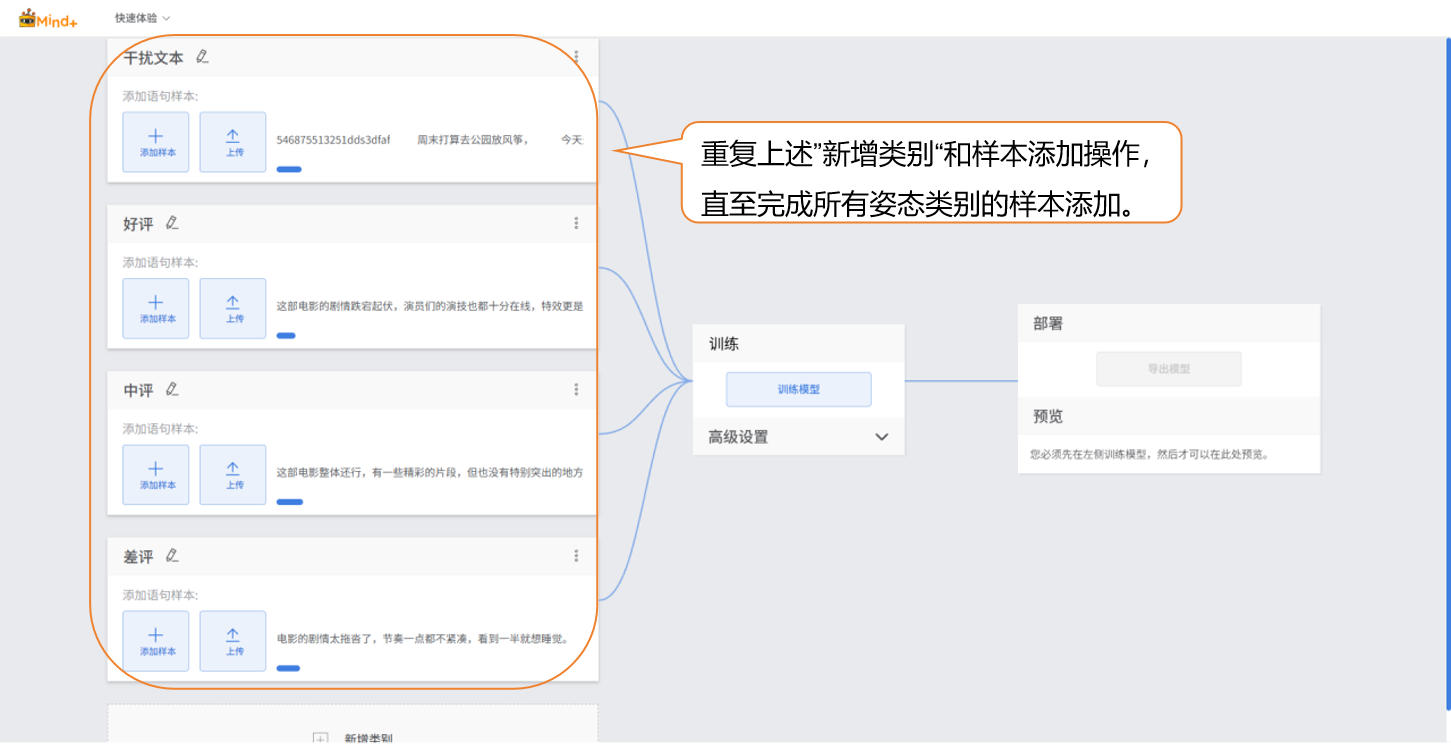
点击“新增类别”,新建另一类别(如“好评”),重复上述样本添加操作,直至完成所有类别的样本添加。
-
-
-
数据样本小提示:
-
- 每个数据类别可准备多样化的样本文本,类别间数量尽量平衡。
- 建议给类别起个简洁的名字,不要用太复杂的符号或过长的名称。
-
步骤3:训练模型¶
-
高级参数设置
-
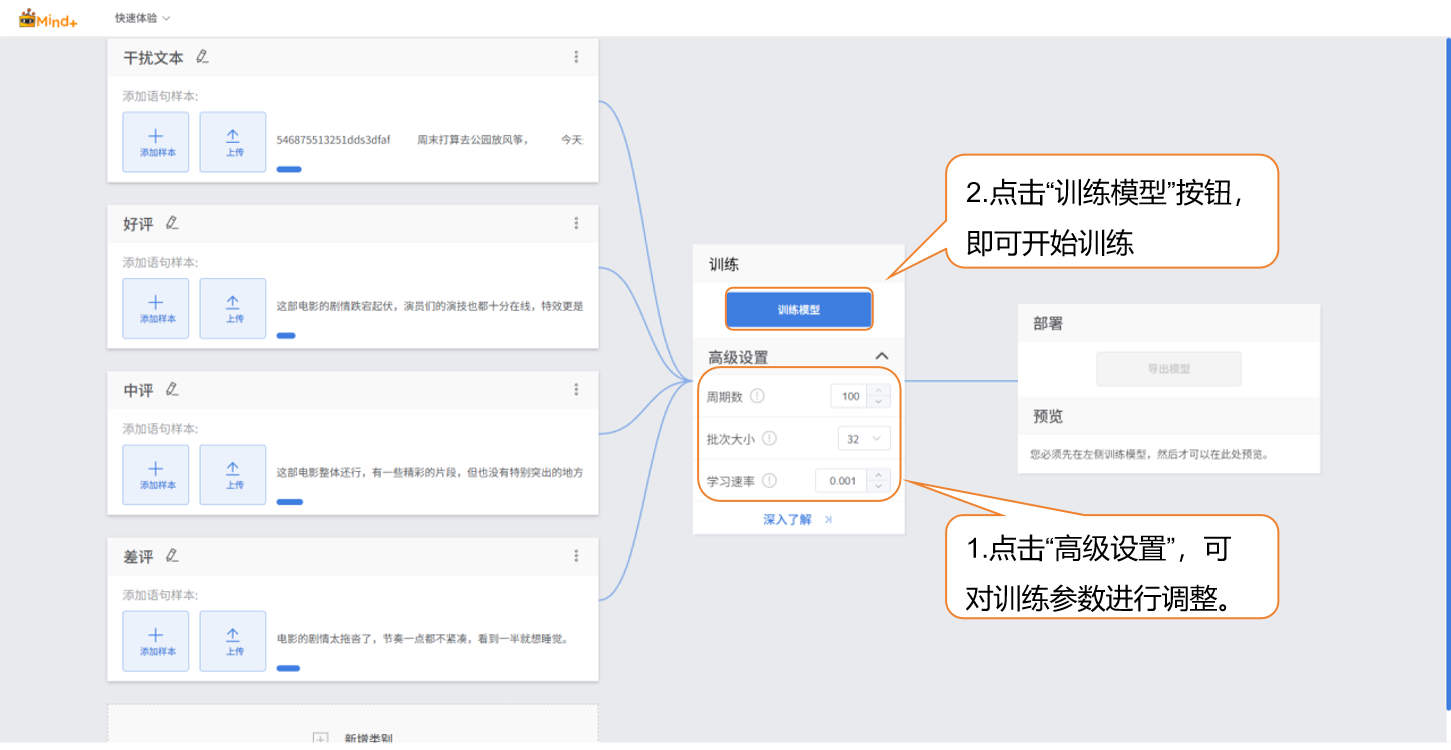
在训练模型前,点击“高级”设置训练参数,可设置以下 3 个核心参数:
-
参数 参数说明 类别说明 推荐设置 周期数(Epochs) 一个周期指训练数据集中的所有文本样本均已向模型馈送并完成一次参数更新。例如,周期数设为 30,即模型对全量训练样本迭代学习 30 次。 反映模型对训练文本特征的学习深度:周期数不足易导致欠拟合(分类准确率低,无法识别常见电影评论类别);周期数过多可能导致过拟合(对训练文本分类准确,但对新文本分类误差大)。 100 批次大小(Batch Size) 模型每次训练时同时处理的文本样本数量。例如,批次大小设为 12,即每次从训练集中抽取 12 条文本进行特征计算(如情感词提取、语义编码)与参数更新。 影响训练速度与模型稳定性:批次过小会增加训练耗时(需更多迭代次数),且参数更新波动大;批次过大可能导致内存不足(文本特征处理需占用内存),或模型收敛困难(单次更新覆盖样本过多,难以调整参数)。 32 学习速率(Learning Rate) 控制模型每次参数更新的步长,即模型根据文本分类误差调整权重的幅度。例如,学习速率设为 0.001,即每次参数更新幅度为 0.001 倍的梯度值。 决定模型训练的收敛速度与最终精度:速率过大易导致训练震荡(误差忽高忽低,无法稳定收敛);速率过小会使训练缓慢(需更多周期才能达到低误差),且可能陷入局部最优解。 0.001 -
启动模型训练
-
完成训练参数设置后,点击 “训练模型” 即可开始训练(若不做设置,也可直接使用系统默认参数)。
-
-
训练过程中,请务必保持此标签页为打开状态,避免切换页面或关闭浏览器导致训练中断。
-
训练过程监测
-
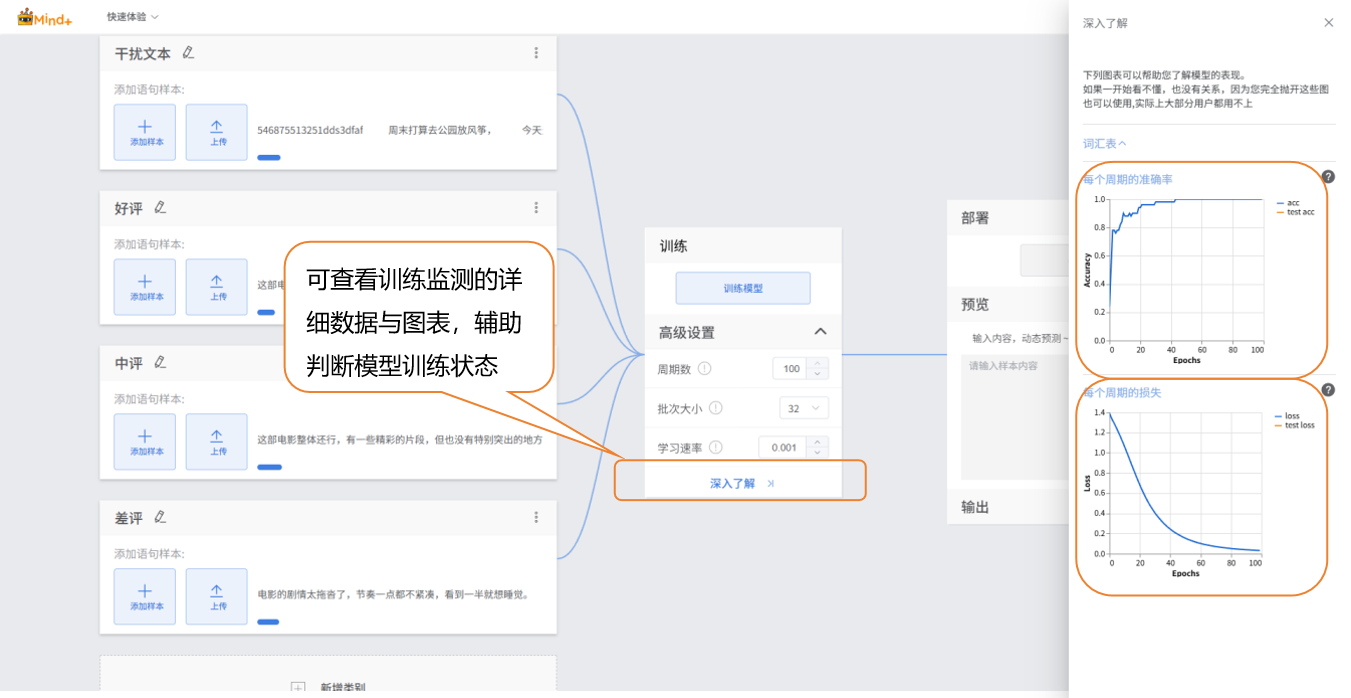
在训练模型过程中,可通过点击“深入了解”按钮,查看训练监测相关数据。
-
- 每个周期的准确率: 是指在模型训练的一个周期(即对整个训练数据集完整迭代一次)内,模型预测结果与实际结果相符的比例。
- 每个周期的损失: 则是该周期内模型预测值与真实值之间的误差程度量化指标。
-
步骤4:模型校验¶
- 模型训练完成后,可以通过校验区,检验模型效果。
-
小提示:用一些未参与训练的新文本进行测试,更能反映模型实际效果。
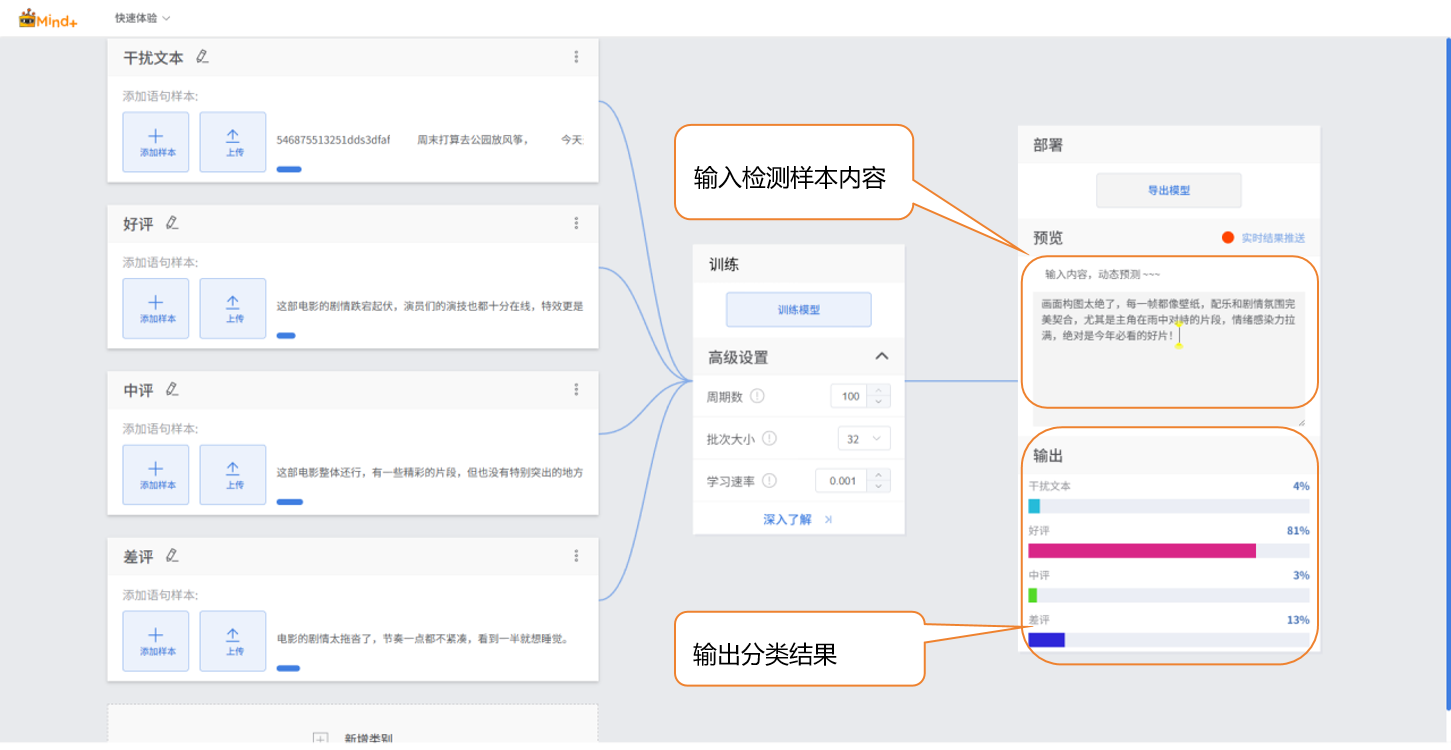
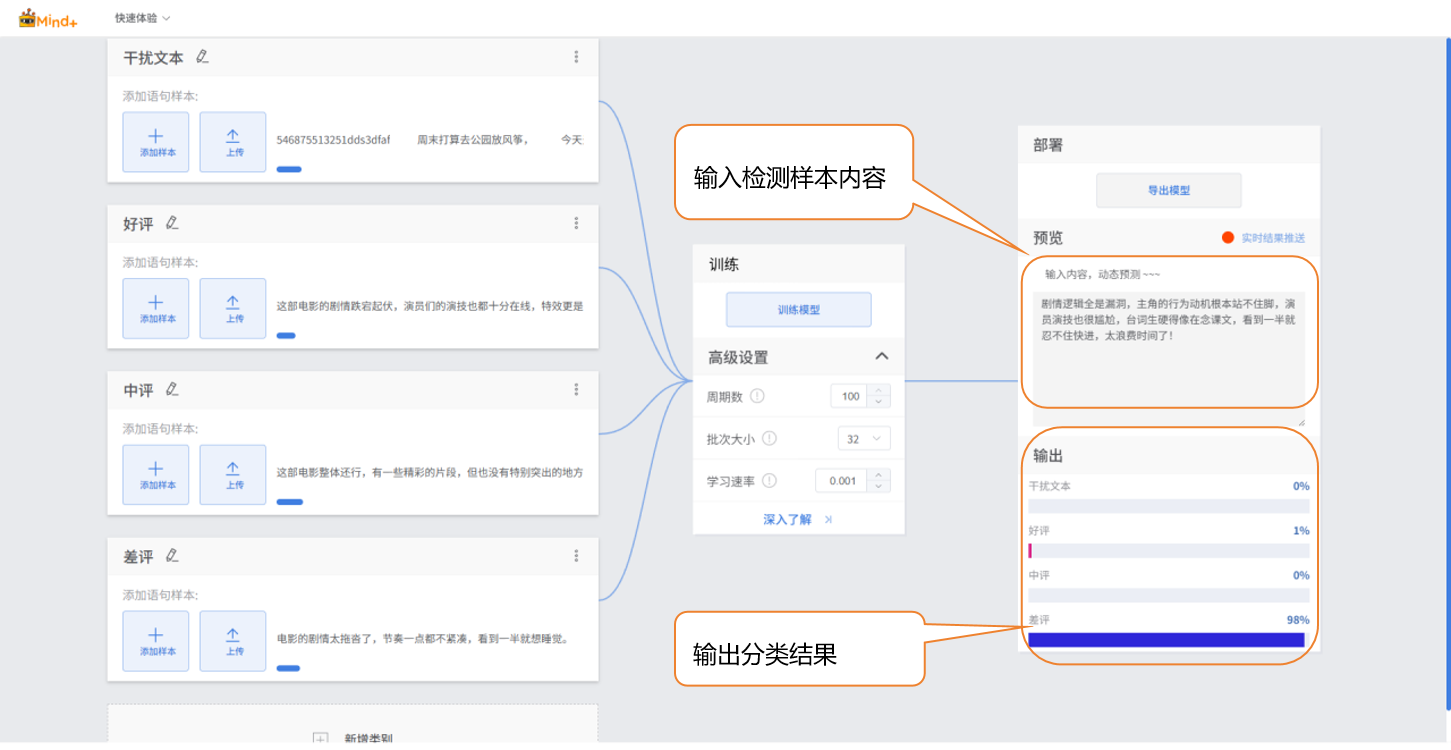
- 检验方式:输入文本
- 在 “输入” 区域点击 “手动输入” 选项,在文本框中输入新的电影评论文本内容,界面 “输出” 区域会显示实时分类结果。
-
-
校验结果分析:
- 若校验准确率≥80%:说明模型满足基础应用需求,可进入部署阶段;
- 若校验准确率 65%-80%:需优化模型,可补充该类别样本
步骤5:模型导出¶
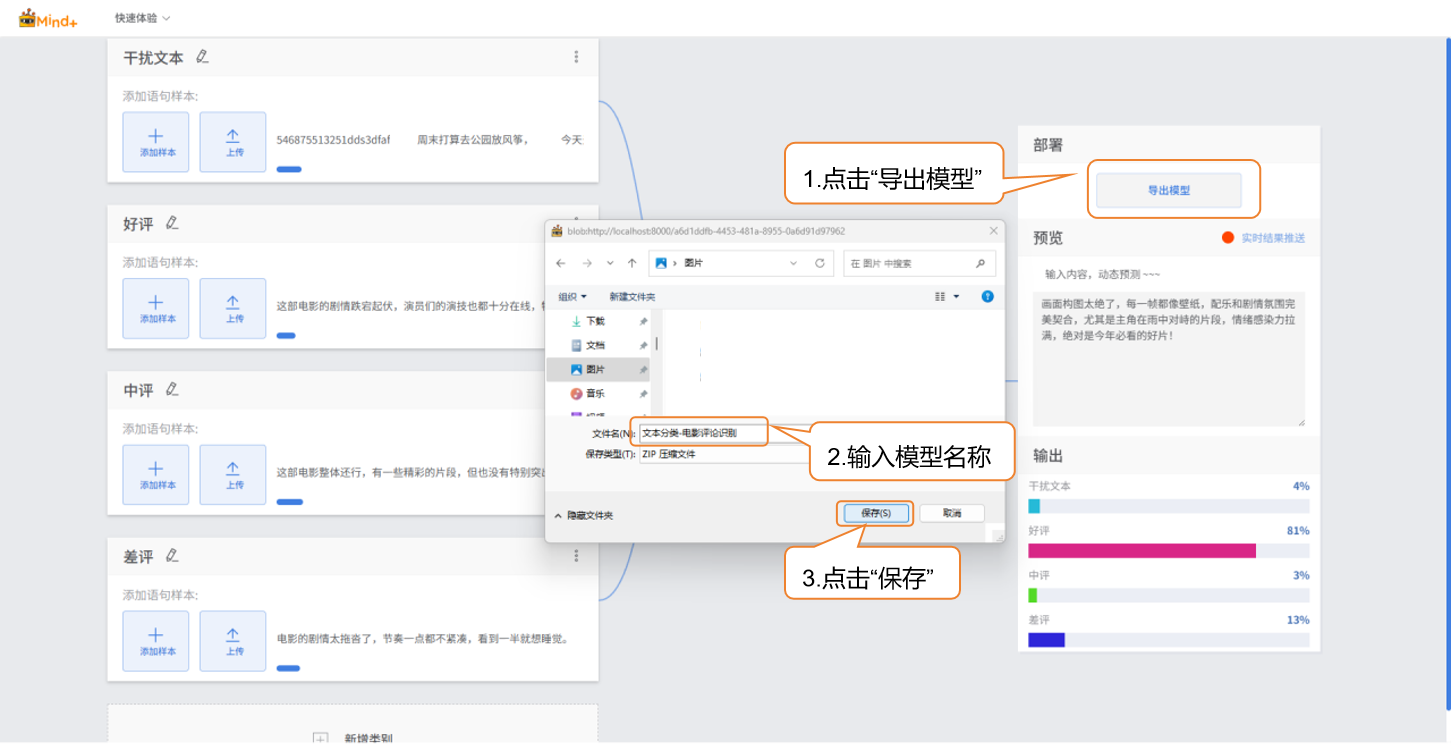
- 当模型校验结果满足需求时,就可以进入部署阶段。
- “部署” → 点击 “导出模型”。
- 平台支持将模型导出为zip格式,便于在其他环境中使用或进行二次开发。
步骤6:模型部署¶
方法一:参考4.1.4 模型部署
- 适用:支持硬件部署的模型(如行空板M10/K10),如图像分类、目标检测等模型。
方法二:参考4.1.5 实时结果推送
- 适用:暂不支持硬件部署的模型,如语音识别、文本分类等模型。
模型训练常见问题¶
- 在模型训练过程中,可能会遇到各种问题,例如训练速度慢、精度不理想或参数设置不当。下面整理了常见问题及解决思路,帮助你更顺利地完成模型训练。
| 常见问题 | 导致的原因及解决方法 |
|---|---|
| 模型准确率不高 | 可能原因:样本数据数量不足样本类别不平衡训练参数设置不合理解决方法:补充样本:每个类别样本增至20-30 个,覆盖不同表述风格、情感倾向等尽量保持各类别样本数量均衡,以提升模型的准确率。调整周期数、批次大小、学习速率等训练参数。 |
| 训练时间过长 | 可能原因:批次大小设置过小,每次训练处理的文本量少,导致训练轮次需要更多时间;训练轮次设置过大,模型重复学习数据太多。解决方法:适当增大批次大小,让模型每次处理更多文本,加快训练速度;根据数据量和任务需求合理调整训练轮次,避免不必要的重复训练。 |