1-前言
Mind+ V1.5.6及以上版本增加了语音识别及语音合成功能,无需智能硬件,方便大家零成本体验最新的语音识别及合成技术。
注意:
- 本功能需要电脑具有良好的网络,使用的服务为百度大脑;
- MInd+仅根据百度大脑提供的技术文档将网络访问以积木块形式呈现,数据直接与百度大脑服务器进行交互,因此识别准确度、稳定性、是否收费等均由百度大脑服务器决定,请关注百度大脑后台说明;
- Mind+端程序积木可能会因为百度提供的服务变更而出现功能失效或调整,请关注常见问题;
- 如需离线运行可使用硬件模块,或使用开放扩展库接入其他AI服务
2-快速上手教程
2.1-准备工作
- 电脑 x1
- 麦克风 x1
- 扬声器 x1
- 其他:电脑良好的联网
2.2-加载功能扩展
- 切换到实时模式
- 打开扩展
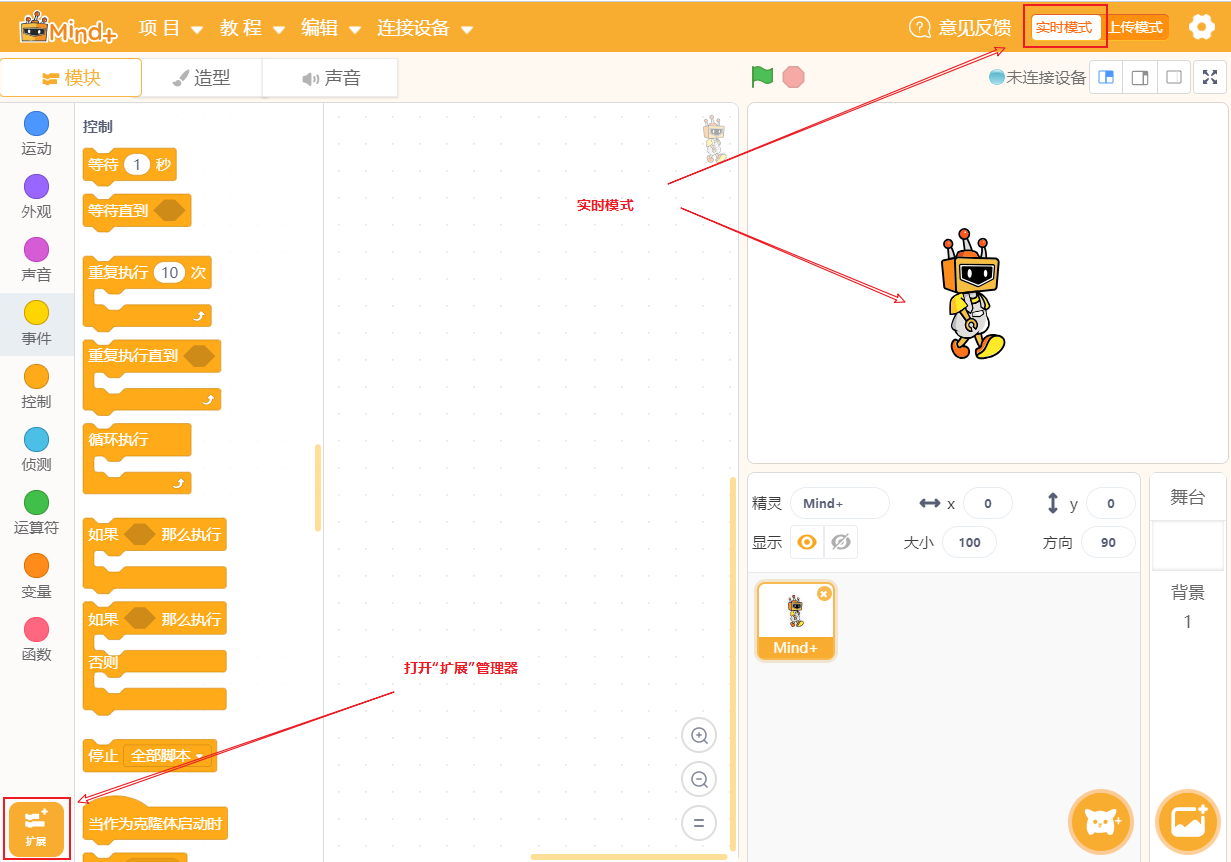
- 切换到“功能模块”,加载“文字朗读”和“语音识别”,之后“返回”主界面
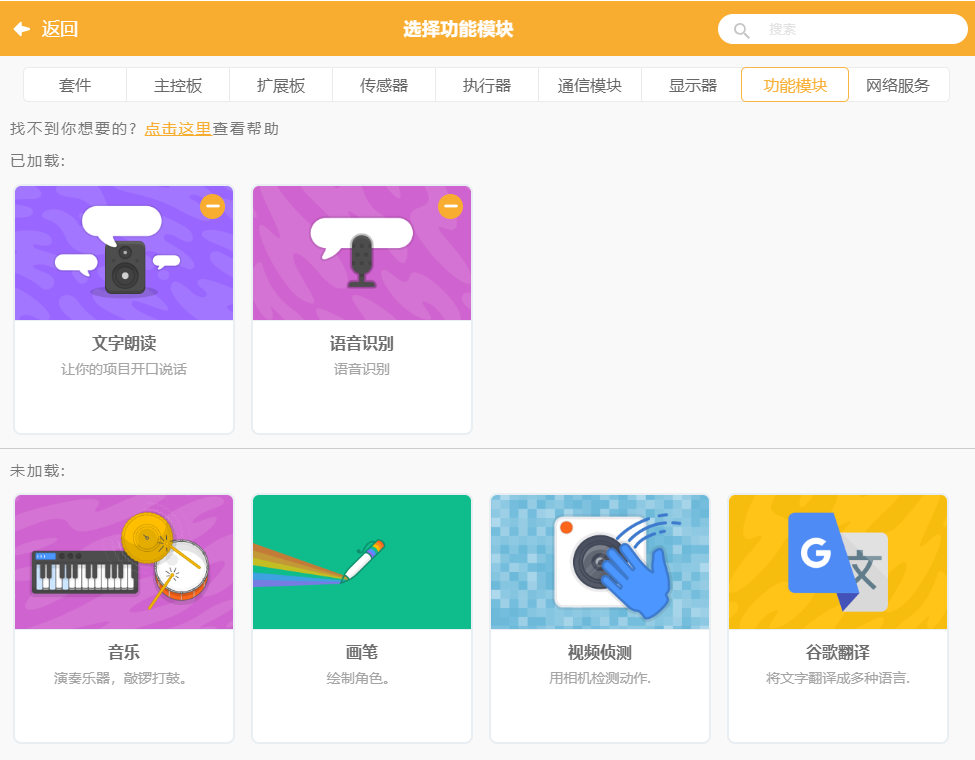
2.3-语音问好
- 拖动积木块,完成如下程序:
注:如果提示额度已满,请查看后文“常见问题”
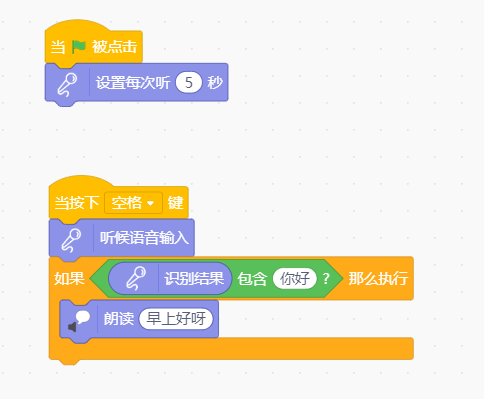
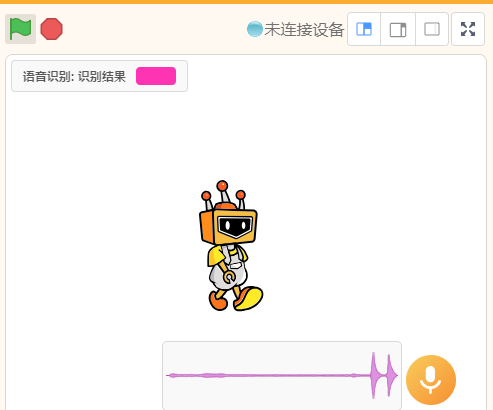
- 当点击绿旗后,舞台显示声波图,对着电脑麦克风说出“你好”,等待片刻,将会得到回答“早上好”。
注:如无法识别,请查看本文最后的常见问题
-------------
3-积木说明
3.1文字朗读相关积木
| 积木 | 说明 |
|---|---|
 |
使用电脑喇叭播放文字声音 |
 |
设置服务器1使用不同的嗓音播放声音。注意其中“小猫”没法发出人声 |
 |
设置服务器1使用不同的语言播放声音 |
 |
Mind+中语音识别有两个服务器,服务器1为MIT服务器,在国外,服务器2为百度服务器,在国内。因此当一个服务器没有反应时可以尝试使用此模块切换到另一个服务器。。 |
 |
设置服务器2的嗓音。注意后面的嗓音使用次数有限,因此请使用前面能用的嗓音。 |
 |
设置服务器2使用不同的语言播放声音 |
 |
使用服务器2时可以切换至独立账户,与人脸识别账号通用 <点击查看> |
3.2-语音识别相关积木
语音识别原理:录音一段时长并上传到云端做识别然后返回结果。
| 积木 | 说明 |
|---|---|
 |
Mind+内置了一个公共账号,额度如使用完毕则需要使用此积木切换至服务器2的独立账户,与人脸识别账号通用 <点击查看> |
 |
事件程序,当开始语音输入之后得到的结果为此事件程序设定的结果时触发。 |
 |
开始录音,直到设置的“每次听的时间”结束或者执行“语音识别结束听”。 注意:开始语音输入时请保持周围环境安静或者使用独立麦克风。 |
 |
返回识别的结果,前面勾选之后舞台可以直接显示结果。 |
 |
设置每次录音时长,到时间后自动结束听,最长60秒。 |
 |
提前结束语音识别过程并上传录音获取识别结果。 |
 |
可以显示或者隐藏声波提示图,默认开启。  |
 |
Mind+中语音识别使用了两个服务器,服务器1为MIT服务器,在国外,服务器2为百度服务器,在国内,默认为服务器2。因此当一个服务器没有反应时可以尝试使用此模块切换到另一个服务器。 |
-------------
4-应用教程
5-常见问题
| 问题点: | 提示额度满了怎么办?  |
| 解决办法: | 免费公用账户使用额度满了,可以切换到自己的百度AI账户,与人脸识别账号通用,注册后领取免费额度,如需长期使用可以实名认证后付费使用。 详细操作说明:点击查看 |
| 问题点: | 是否可以脱离电脑使用或无限次使用? |
| 解决办法: | 实时模式的语音识别依托网络实现,如果要离线使用需要配合相应的硬件,语音识别模块。 |
| 问题点: | 语音识别波形图没有反应。 |
| 解决办法: | 检查一下电脑麦克风是否连接正常,驱动安装正确,可以搜索相关电脑麦克风问题。 |
| 问题点: | 语音识别速度慢。 |
| 解决办法: | 请保证电脑良好的网络,若网络不好,可以切换至独立服务器。 |